Motif injection and sequences’ labels.
simulation_description.RmdSequence data simulation
We generate sequences of length based on real frequences of amino acids on full alphabet.
| A | L | A | V | P | H | G | K | T | F |
| S | L | Q | W | E | P | V | L | D | T |
| R | I | F | N | N | V | Q | G | A | A |
| G | C | S | D | G | Y | D | Q | T | R |
| Y | L | R | R | S | R | P | D | A | V |
| N | V | S | M | M | T | R | G | D | I |
Motif generation
We generate a set of motifs () with the following parameters:
| A | _ | _ | B | ||||
| Y | L | _ | G | _ | _ | D | |
| N | _ | _ | _ | _ | M | ||
| A | B | _ | T |
Motif injection
We inject motif by replacing a randomly selected part of a sequence with this motif. For example:
| A | L | A | V | P | H | G | K | T | F |
| S | L | Q | W | E | P | V | L | D | T |
| R | I | F | N | N | V | Q | G | A | A |
| G | A | B | D | T | Y | D | Q | T | R |
| Y | L | R | R | S | R | A | B | A | T |
| N | V | A | B | M | T | R | G | D | I |
We inject from to motifs to a single sequence according to the following procedure:
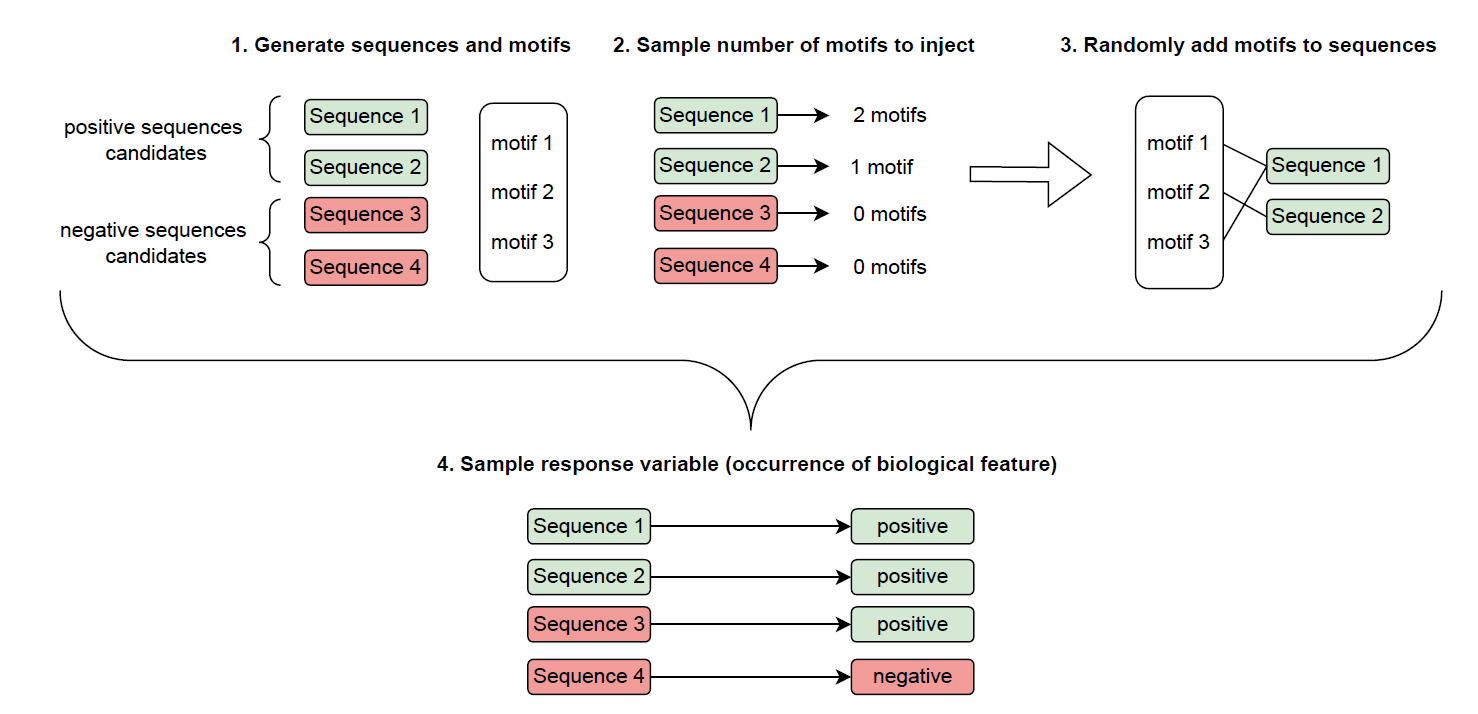
Target variable sampling
Let’s define a random variable on a set of sequences which describes whether a sequence is a subsequence of . Namely, for any sequence :
where means that is a subsequence of . For example
Logistic regression
In this case we consider a standard logistic regression model where the joint effect of all motifs is the sum of their individual effects. Let be weights related to motifs . Let be an effect for the sequences without motifs. Then, we can define an additive logistic model as follows:
We assume some particular values of and calculate vector of probabilities as follows:
Having we simulate from binomial distribution .